


Präferenzanalyse: Wer mag was?
Dr. Stefan Ryf
Menschen mögen manche Dinge mehr als andere – sie haben also Präferenzen. Das Schöne aus Sicht der Marktforschung ist, dass sich Präferenzen leicht erfassen lassen. Denn im Vergleich zu vielen anderen typischen Fragen in der Marktforschung ist die Frage, ob man etwas mehr oder weniger mag, einfach zu beantworten, und man teilt sein Urteil auch gerne mit – was sich ja auch in der alltäglichen Kommunikation häufig zeigt.
Bloss: Allein aufgrund der Präferenzangaben weiss man ja noch nicht, wieso eine Person etwas mag oder eben nicht. Kennt man allerdings die Präferenzen von vielen Personen zu verschiedenen Objekten eines Bereiches (zum Beispiel zu Automarken, Erfrischungsgetränken oder Ferienangeboten), so lässt sich daraus mit geeigneten statistischen Verfahren die grundlegende Struktur hinter den Präferenzen aufdecken. Was faszinierende Einblicke in die Dimensionalität und inhaltliche Gruppierung des jeweiligen Gebietes ermöglicht, die sonst nicht so einfach offenliegen. Im Folgenden zeige ich Ihnen eine mögliche Vorgehensweise am Beispiel der Vorlieben für Musikinterpreten.
In einer Studie unserer Forschergruppe wurden Präferenzurteile zu 200 Musikinterpreten auf einer Skala von 1 bis 6 (mit den Endpunkten ‚höre ich gar nicht gerne’ bis ‚höre ich sehr gerne’) erhoben. Die 207 Teilnehmenden wurden darauf hingewiesen, nur Interpreten zu bewerten, die sie gut genug kennen, um ein Urteil abgeben zu können. In einem ersten Auswertungsschritt können jeweils zwei Musikinterpreten miteinander verglichen werden. In Abbildung 1 sind zwei solcher Paarvergleiche mit den entsprechenden Präferenzverteilungen dargestellt. Die Grösse der Kreise in der Abbildung zeigt an, wie viele Leute die jeweilige Kombination von Präferenzwerten aufweisen. Wie deutlich zu sehen ist, halten Personen, die den Künstler Beck hoch bewerten, von der Musikgruppe Destiny’s Child nicht so viel, und umgekehrt (linkes Diagramm). Destiny’s Child und Beck sprechen also ein völlig verschiedenes Zielpublikum an und unterscheiden sich offenbar in wichtigen Kriterien, die für die Präferenzbildung eine Rolle spielen, was sich statistisch in einem negativen Korrelationswert zeigt (r = -.48). Anders sieht es dagegen bei der Paarung Ashanti und Beyoncé aus (rechtes Diagramm): Dort finden die meisten Leute entweder beide gut oder beide schlecht, aber es gibt fast keine Personen, die die eine gut finden und die andere schlecht. Sie müssen sich demzufolge bezüglich der Präferenz-relevanten Kriterien sehr ähnlich sein. Entsprechend ergibt sich ein hoher positiver Korrelationswert (r = +0.68).
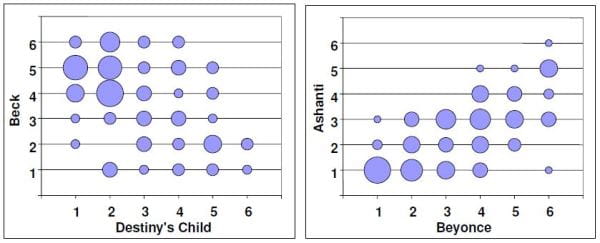 Abbildung 1: Beispiele für Präferenzverteilungen bei Paaren von Musikinterpreten
Abbildung 1: Beispiele für Präferenzverteilungen bei Paaren von Musikinterpreten
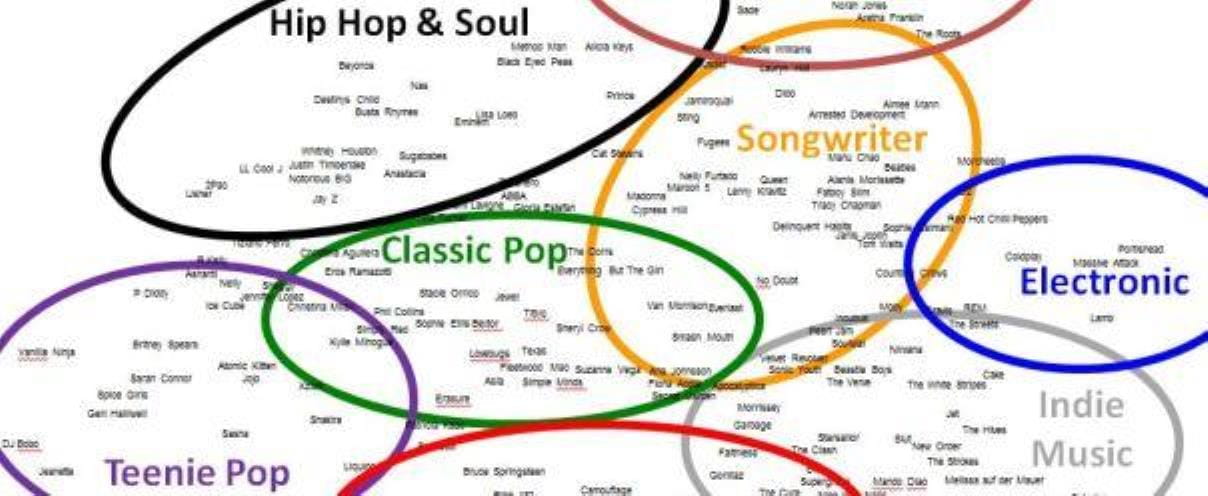
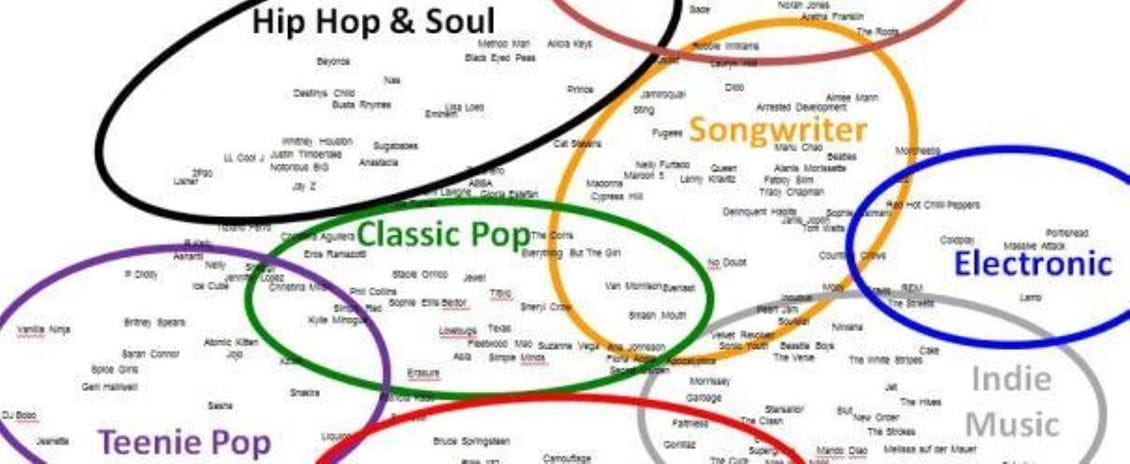
Solche Korrelationswerte werden nun für alle möglichen Kombinationen von Musikinterpreten berechnet (bei 200 sind das immerhin schon 19‘990 Paare). In einem zweiten Auswertungsschritt werden diese Werte dann mit geeigneten statistischen Verfahren analysiert. In diesem Fall wurde eine „nonmetrische multidimensionale Skalierung“ (NMDS) verwendet, um die Daten bestmöglich auf zwei Dimensionen abzubilden. Somit wurde also quasi eine „Landkarte“ des Musikmarktes erstellt (Abbildung 2) und die gefundenen Unterschiede sinnfällig interpretierbar gemacht. Denn in dieser Karte sind Musikinterpreten, welche die gleichen Personen ansprechen, nahe beieinander. Musikinterpreten, die sehr unterschiedliche Zielgruppen ansprechen, sind dagegen weit voneinander entfernt.
Mit genügend Wissen über die Künstler kann die Karte nun auf ihre intuitive Interpretierbarkeit hin überprüft werden. Dabei fallen viele sehr direkte Nachbarn auf, bei denen diese Platzierung durchaus nachvollziehbar ist: Miles Davis und Keith Jarrett (Helden des Jazz) / Portishead, Massive Attack und Lamb (innovativer Elektro-Sound mit weiblichem Gesang) / Beck und PJ Harvey (eigenständige alternative Künstler) / Notorious B.I.G. und Jay-Z (Rap-Ikonen) und viele mehr. Geri Halliwell ist direkte Nachbarin von den Spice Girls, Beyoncé von Destiny’s Child – beides (ehemalige) Sängerinnen der jeweiligen Musikgruppe.
Aber auch bei der Verteilung der Künstler über die verschiedenen Bereiche der Karte lassen sich Muster erkennen. In Abbildung 2 ist eine mögliche, grobe Kategorisierung der Karte dargestellt und mit (plakativen) Bereichsbezeichnungen versehen. Neben der Platzierung der Künstler in und zwischen diesen Kategorien ist aber auch die Anordnung der Kategorien zueinander interessant. Die Kategorie ,Classic Pop’ beispielsweise grenzt zum einen an ‚Rock’, zum andern an ‚Hip Hop & Soul’. Links geht es rüber in den ‚Teenie Pop’, rechts in den Bereich ,Songwriter’.
Natürlich ist die Interpretation dieser Karte teilweise subjektiv, doch zeigt dieses Beispiel, wie Strukturen in den Präferenzen erkennbar gemacht werden können. Anbieter wie Amazon, Facebook oder Google nutzen vergleichbare Verfahren, um die Daten ihrer Nutzer und Kunden zu analysieren. Häufig sind dort die Basis aber nicht direkte Präferenzurteile, sondern Verhaltensdaten wie Einkäufe, angeklickte Beiträge oder ähnliches, die indirekt natürlich auch mit Präferenzen zusammenhängen. Die Grundidee bleibt die gleiche: Durch die Betrachtung der Daten vieler Personen mit unterschiedlichen Vorlieben können die wichtigsten Faktoren für die Präferenzbildung (also eine Art Bauplan) abgeleitet werden. Das kann zum Beispiel dazu verwendet werden, um Empfehlungen an Kunden abzugeben, Produkt-Bundles zusammenzustellen oder Zielgruppen zu definieren.
Diese Seite teilen
